Jenkins is an open source automation server that is often used as a CI/CD tool to run your automated tests and deployment pipeline. It was created in 2011, a while back and has a range of possibilities because of its compatibility with multiple version control tools and scripting. There was a feud with Oracle’s Hudson (now deprecated) with Jenkins each considered the fork of the other one, both having a butler as a logo.
Enough history, Let’s check it out!
UI
Blue Ocean is the name of the new UI look of jenkins, which is more on part with what’s existing with GitLab ci. The older UI is also called Classic UI and is still accessible if you want to burn your eyes or access the advanced settings, like you used to.
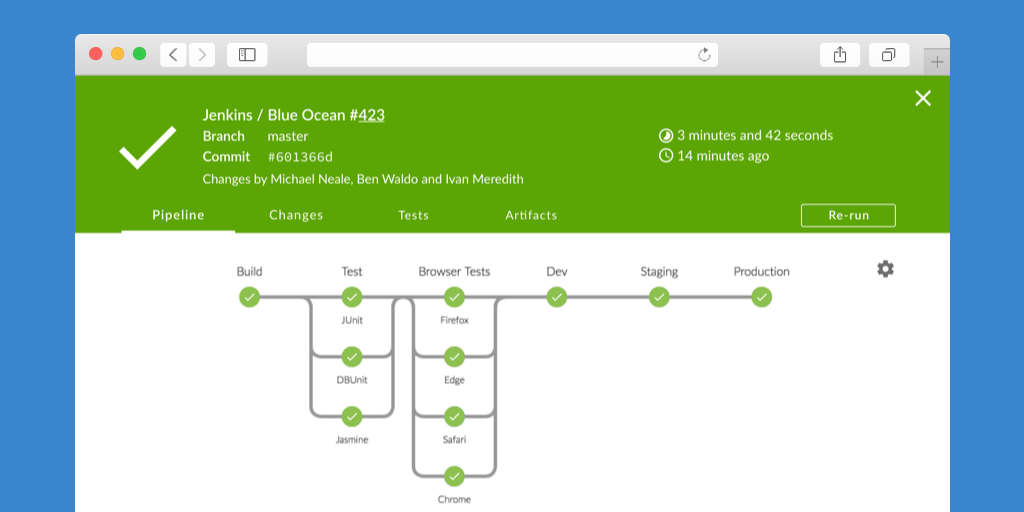
Example from jenkins of the new UI being used. Each step is clickable, the logs are ordered by steps and can be expanded which is much neater than a big chunk of logs.
Syntax
Jenkins’ files are written in groovy, and you will most likely find #!/usr/bin/env groovy or similar at the top
signaling that the syntax should be interpreted as groovy.
Pipeline base
The hierarchy works as follows, pipeline > stages > stage > steps, the executable action should be within the steps part.
The stage’s name will be displayed within the Blue Ocean’s view.
pipeline {
agent { docker { image 'ruby:3.0.3-alpine' } }
stages {
stage('build') {
steps {
sh 'ruby --version'
}
}
}
}
The agent is what will be used to run the executable parts, here it’s a docker, but you could use it with a label within
your organisation with a label such as agent { label 'large' }.
You can also set in your pipeline the environment which can be used across your stages.
environment {
VERSION = "3.0.3-alpine"
}
Which can then be used as env.VERSION or within a bash script as ${env.VERSION}. However, the value is immutable and
can’t be reassigned later.
Parallel Steps
You can also use parallel to run two stages and their step at the same time within a stage.
The parallel can’t be dangling right below stages which means you may need to get creative for that wrapper stage’s
name. Here I called it “Integration”, I guess that’s good enough for the example 🤷♀️
stage('Integration') {
parallel {
stage('Contract tests') {
steps {
// ...implementation
}
}
stage('Smoke tests') {
steps {
// ...implementation
}
}
}
}
You can run two independent steps in parallel, potentially saving time on your overall pipeline time. As shown by the UI before, you can stack as many stages as you want in parallel, keep in mind that you’ll still need an agent and an infrastructure that can match your enthusiasm.
Retry, timeout, input
There are some other pre-defined functions, let’s see an example of the most common ones.
steps {
retry(3) { /* ... */ }
timeout(time: 3, unit: 'MINUTES') { /* ... */ }
}
Those two step needs to be run within a steps block:
- Retry is pretty straightforward and will execute in this example up to 3 times what’s inside the block
- Timeout will wait until the set time (here 3minutes) before executing what’s inside the block
There’s also another one input which is situated at the stage level and will ask for a user input, perfect
if you need to manually parametrize your build:
stage('Example') {
input {
message "Should we continue?"
ok "Yes, we should."
submitter "alice,bob"
parameters {
string(name: 'PERSON', defaultValue: 'Mr Jenkins', description: 'Who should I say hello to?')
}
}
steps {
echo "Hello, ${PERSON}, nice to meet you."
}
}
You can see here that the PERSON variable is not declared before and is assigned to the value set in the input.
You can also use a different type of input with $class and a parameter definition class such as ChoiceParameterDefinition,
for a choice (a dropdown list) as a parameter input:
[$class: 'ChoiceParameterDefinition', choices: 'yes\nno', description: 'Am I a pipeline?', name: 'ANSWER']
You can see that the choices are separated from each other by a \n, the rest stays similar. If you need an example
on how to use the parameter’s definition class, you can always find some on GitHub from famous open source projects.
Scripts
You can also use some code in those groovy jenkins files, since the variable defined in the environment are immutable,
you can declare actual variables using def variableName = 'hello world'.
You can define those variables outside the pipeline block, as well as creating other methods. If you want to add
some logic from within a step you would need to use a script block:
step {
script {
def browsers = ['chrome', 'firefox']
for (int i = 0; i < browsers.size(); ++i) {
echo "Testing the ${browsers[i]} browser"
}
}
}
You can also have, if/else, try/catch in your scripted pipeline, but usually you’ll want to extract big complex block of logic into a shared library to keep your pipeline lean.
Customization
You can create shared libraries in jenkins to reduce redundancy when working with multiple pipeline,
for that you’ll need to write your steps in groovy in a vars folder and the name of the file in camelCase will be
its identifier.
For complex steps, you can also have some groovy class in a src folder.
//vars/withMainBranch.groovy
def call(Closure body) {
if (env.BRANCH_NAME =~ /main/) {
body()
}
}
The Closure type is when the step is called with a block aka something within { .. }, the body within that block
can then be executed. For in this example, the block will only be executed if the BRANCH_NAME (which is a default Jenkins
env variable) matches main:
withMainBranch {
echo "This is the main branch"
}
You have the possibility to declare more than one behaviour, like this simple example from the
jenkins documentation where the log steps gets defined with two functions:
//In vars/log.groovy
def info(message) {
echo "INFO: ${message}"
}
def warning(message) {
echo "WARNING: ${message}"
}
You can also have a matching a log.txt with some information on how to use it.
Which can then be imported and be used by calling the file name as a method, such as:
@Library('utils') _
log.info 'Starting'
log.warning 'Nothing to do!'
It will print out in the log the information as specified by the script.