Let’s talk about MongoDB queries, but first if you are not familiar with this Database, you can check this article which should answer your question What is Mongo DB ⁉️
Now that you know the concept, you want to dig into your new database and explore its content. And for that we are going to use MongoDB Compass which is a free interactive tool for MongoDB by MongoDB.
Connect
The process to connect is very easy, once you have a MongoDB spawn up locally you can just open compass and by default
the URI should work with mongodb://localhost:27017, 27017 being the default port.
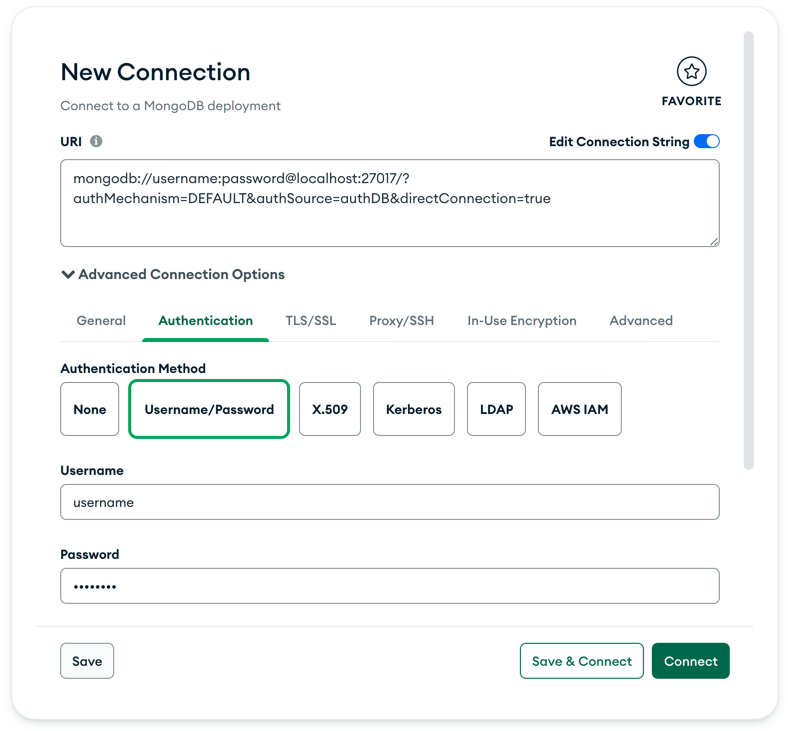
Or as shown above with the advanced option, you can create the connection URI on the fly for example here with password protected
database via direct connection using authDB as its authentication source gives us this:
- URI:
mongodb://username:password@localhost:27017/?authMechanism=DEFAULT&authSource=authDB&directConnection=true
Pretty lengthy to remember! But don’t mind that, click on connect and watch the little animation while you get connected. Used locally, that should not take too long. On the window, you should be able to see the database interface with the collections on the left and the query workplace on the right. Time to query some data!
Query your data
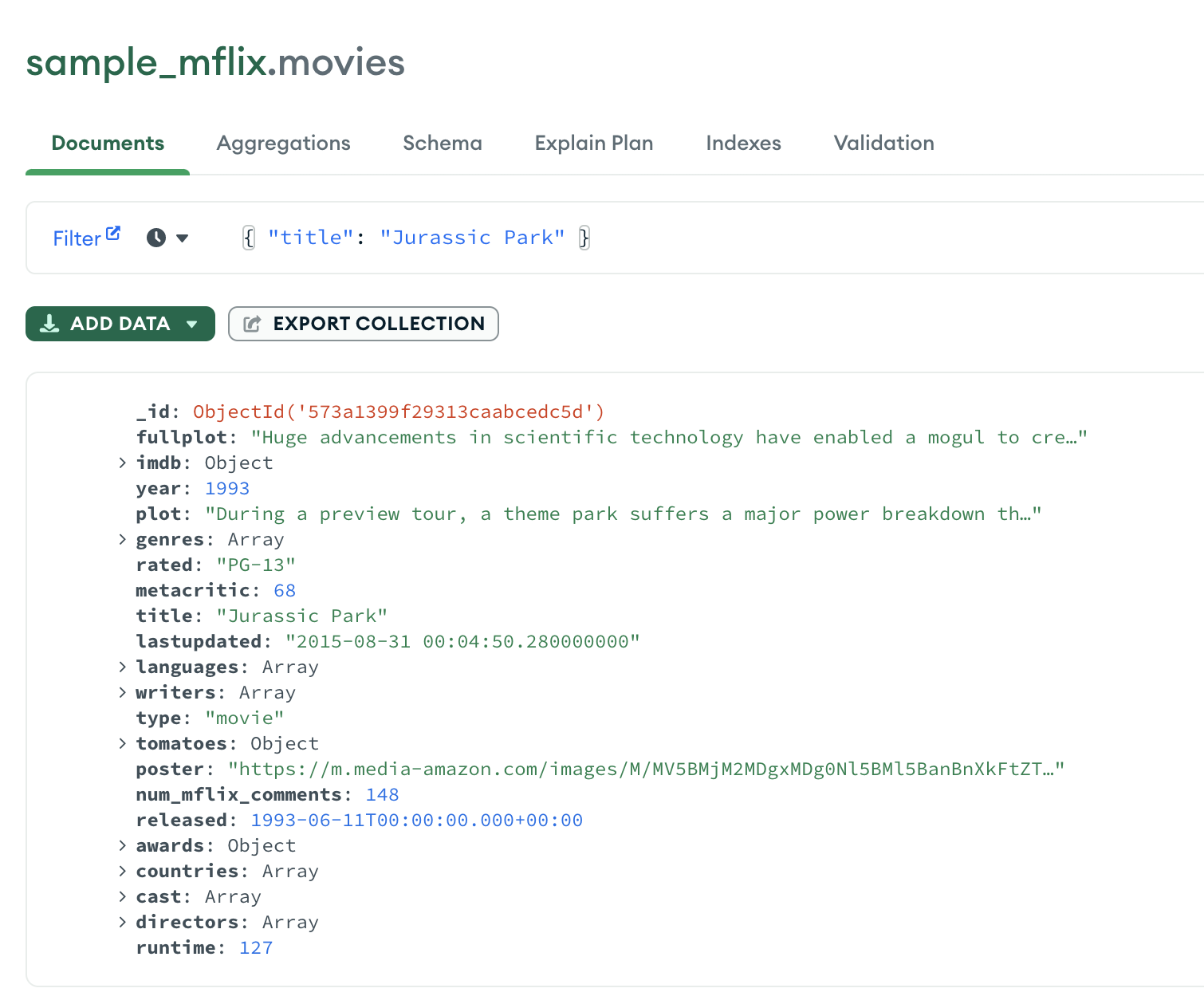
For this part, we are going to use the data from the test collection from MongoDB. Depending on your dataset, or your goal, you may want chose different queries. This is just an overview.
Filters
When querying your data, you may be looking for ways to restrict the amount of result you get from a simple find
operation. And for that you have some useful filters that I like to use:
- Looking for an exact value:
- Example: looking for the document having the field
yearto 1993{ year: { $eq: 1993 } }
- Example: looking for the document having the field
- Looking for values that are not null:
- Example: looking for the document having the field
placenot null{ place: { $ne: null } }
- Example: looking for the document having the field
- Looking for a field within the document or not
- Example: looking for the document having the field named
optional{ optional: { $exists: true } }
- Example: looking for the document having the field named
- Looking for a field matching a regex:
- Example: looking a movie which title is starting with
The{ title: { $regex: 'The .*' } }
- Example: looking a movie which title is starting with
- Looking for a field that is in an array of values
- Example: looking for a movie that is either a comedy or an animation
{ genres: { $in: ['Comedy', 'Animation'] } }
- Example: looking for a movie that is either a comedy or an animation
Obviously there are more than those, but you should be able to cover the basics with $eq, $ne, $exists, $regex and $in in your mongo query toolbox. 🧰
Aggregation
If you click on the right of Documents you can find Aggregations which allow you to create your own aggregation pipeline. As you add more stage you get to see how the data looks like. You also have a recap of all the stages that you have created at the top, and you can order them around which is pretty neat.
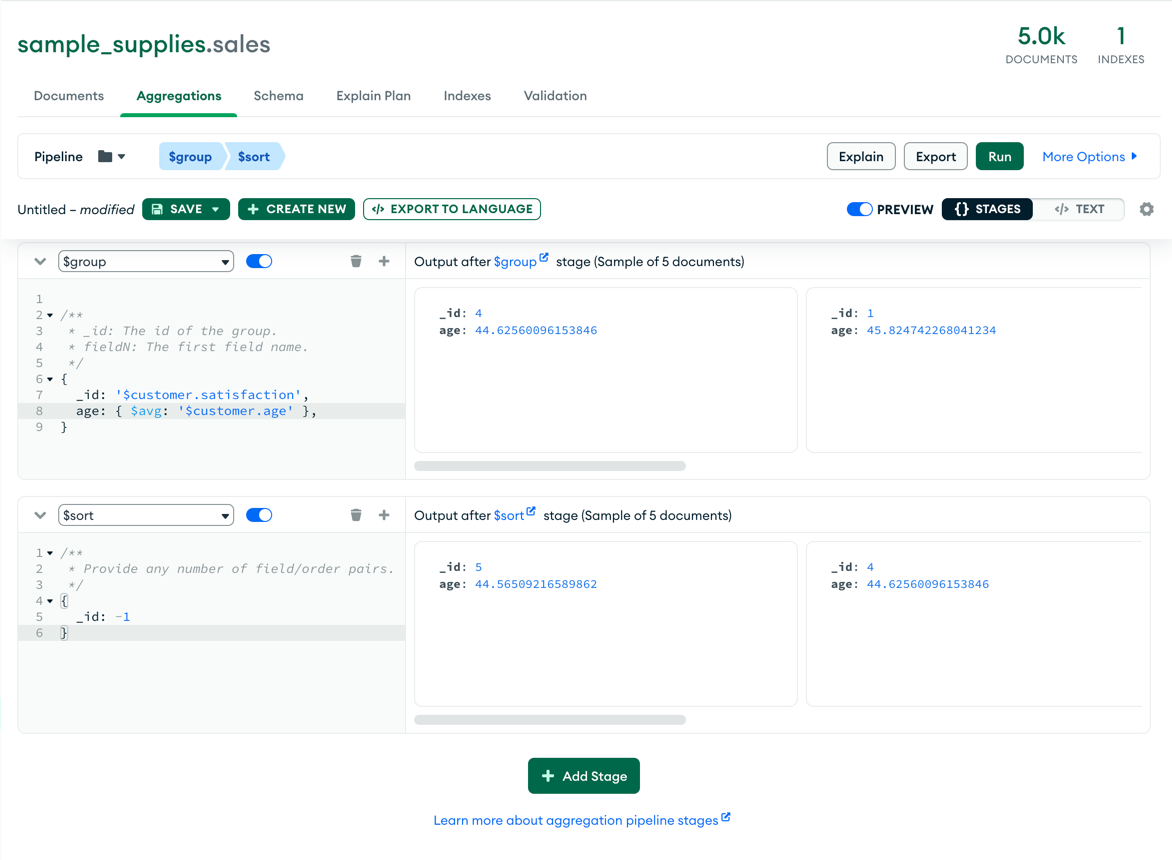
In this collection of sold supplies, I grouped the customer by satisfaction level (from 1 to 5) and then I averaged their age to see if older customer are more likely to be happy than younger ones, and I sorted descending the result on the satisfaction level to see the happiest first.
[
{
$group:
{
_id: "$customer.satisfaction",
age: { $avg: "$customer.age" },
},
},
{
$sort: { _id: -1 },
},
]
Unfortunately this dataset is not very interesting and everybody is around 45 years old. I have pasted here the executed aggregation which you could run from the terminal yourself.
Export to Language
With MongoCompass, you can export your query or in this case your aggregation in the supported language of your choice. For example, let’s export our aggregation query that unwinds the movies by their genre to match all Westerns movies:
from pymongo import MongoClient
client = MongoClient('mongodb://localhost:27017/')
result = client['sample_mflix']['movies'].aggregate([
{
'$project': {
'year': '$year',
'genres': '$genres',
'film': '$title',
'rated': '$rated'
}
}, {
'$unwind': {
'path': '$genres'
}
}, {
'$match': {
'genres': 'Western'
}
}
])
The $project is here just to reduce the amount of data I am working with in this aggregation, and without any other
instruction I have the python code almost ready to use. You would still have to install the dependencies.
That’s a pretty cool feature, which gets even more interesting for typed languages like Java where you can’t just
straight up copy the aggregation json like function into your code for it to work.
If you are having any performance issues, check the how to optimize your query, it’s most likely that you are missing an index or using the wrong one.