For my kanji project, I wanted to generate images for the kanji radicals to replace the placeholder.
Using agents, I thought I could automate the workflow easily. Since it’s an LLM good at writing code, I could have it generate svg files which are possibly something it understood since unlike other image formats, you can “read” it as vectors and such.
First attempt
On the first try, I decided to start generating some, letting the LLM go at it randomly. The agent quickly realised it was time-consuming and wanted to create a script to accelerate things. That script just made a circle in multiple colors for each radical, not more useful than a placeholder.
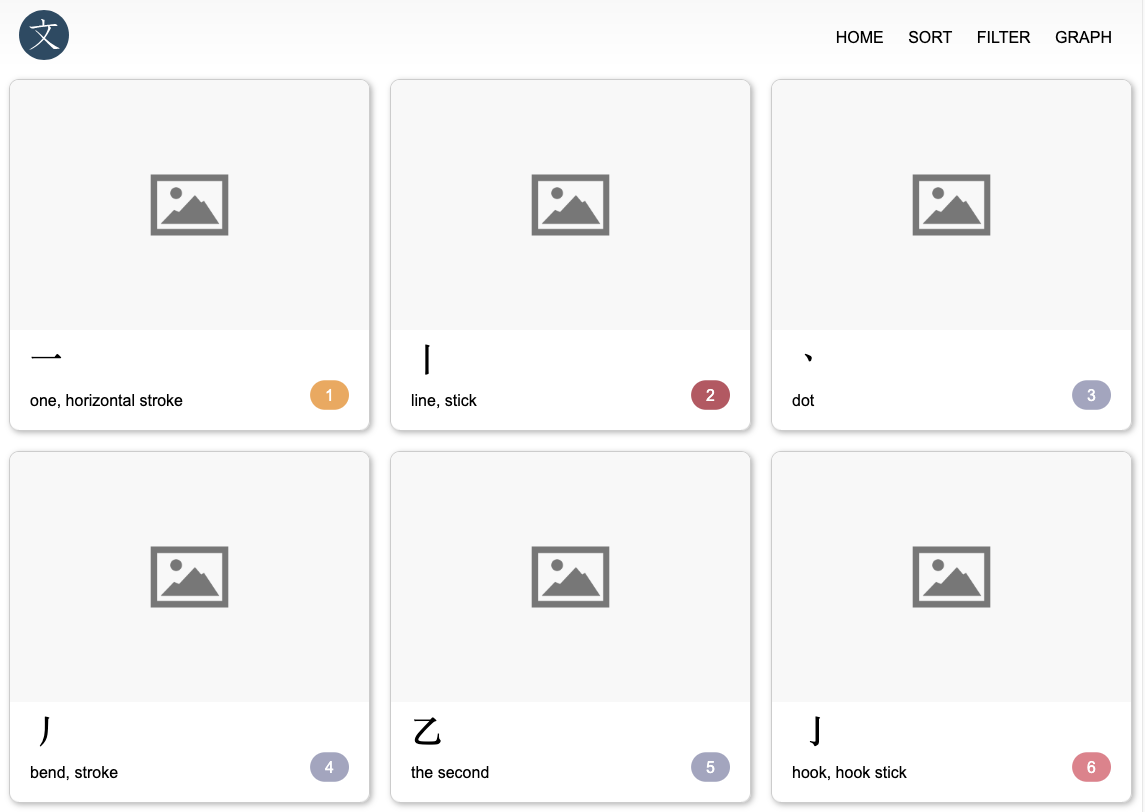
So I prompt it to be more systemic, creating one at a time for more creativity. I had interesting response after each generation the LLM was over emphatically praising its creativity and the beautiful images it was generating…
However, I have to keep on reminding the agent to continue until it had done all 214 of them. Which was more and more complicated as we had completed more, since it had to look for missing ones, and needed additional help to validate it was going in the right direction.



The results were sub par, with some surprising good ones. I think it did confuse some of the radicals’ number with their meaning. There was a more cow looking image than the above one, that was saved under “tile”. To be fair, some of the radical have no real meaning and are quite hard to represent, even by a human.
But the real problems were the inconsistency in size and composition of the images. They should be all the same size for ease of use, and represent something simple memorable.
Improving the process
Fixing those issue manually was not really an option, as I wanted to keep the process automated. So I decided to go with a more organised approach for a second attempt. Actually, I did try other approaches generating and based on learnings, I came up with some strategies to improve the results.
- The radical yaml file with the kanji radicals, categories and their meaning was broken done into smaller files
- this means less information to process at once, and more focus on the task
- I asked the LLM to generate prompts for each radical
- so it would be more specific and less generic on what the image should represent
- In those attempts, I tried having the composition of the svg (what should be there and where) but it was too complex for the LLM to handle
- The agent was progressing per batch to generate the images
- instead of one agent trying to create one image at a time, the agent would ask for 10 at a time, faster and still focused
- there is a balance between to have between too slow but hyper focused or too fast and having only 10% of the job done
- Add a validation step
- To make sure the svg are correctly generated, not empty or broken, at the right size






It was slightly faster, and did produce some more interesting images. But not quite yet what I’d hope …unachievable artist-like quality? Now that I reflect on it, maybe I was hoping to get something similar to chineasy, but the prompting ended up being about representing the meaning of the radical, not the kanji itself.
I also generated the prompts, without carefully reviewing them. I realized that late in the process, it had given me some duplicates, errored or silly ones in the process:
- number: 144
meaning: to go
# Probably from "to say" but could have been duplicated over multiple radicals during tries
composition: Human mouth with speech bubbles
- number: 146
meaning: cover, west
composition: Human hand calculating with tools
- number: 209
meaning: nose
composition: Human nose with breathing and smell function
While using LLM to generate images quickly sounded like a clever workaround to time/memory costly image generation,
but I was starting to think that it was not as clever as I first imagine.
Or perhaps, I just kept changing my mind since I couldn’t get the results I wanted,
and going all in for prettier image seemed like a reasonable next step.
Unaware of the quality of the prompt I had generated, I then continued on the path to generate images directly with an image generation model.
Image generation
Though, every AI product have rate-limit or need paid subscription, so I was wondering how to experiment more freely.
Which led me to Hugging face, they do have a free tier, which I obviously burnt through the monthly token allowance in minutes. But that was not the end goal, because since my machine is not too bad, I thought of generating the image myself using an open source model. Hugging face provides tool to make a script for the image generation procedure.
from diffusers import StableDiffusionPipeline
import torch
# Check MPS availability
device = "mps" if torch.backends.mps.is_available() else "cpu"
# Load model with M4-optimized settings
pipe = StableDiffusionPipeline.from_pretrained(
"runwayml/stable-diffusion-v1-5",
torch_dtype=torch.float32, # float32 works better on MPS
safety_checker=None # Disable for speed
)
pipe = pipe.to(device)
pipe.enable_attention_slicing() # M4 memory optimization
# Generate image
prompt = "Japanese mountain kanji, black brush stroke"
image = pipe(prompt, num_inference_steps=20).images[0]
image.save("m4_generated.png")
# Clean up MPS memory
torch.mps.empty_cache()
Couple of things, I learnt:
- You’ll need a lot of memory,
- 32GB was not enough for some of the latest high quality models.
- Make sure you cap out the memory the process can use (or it’ll probably eat it all and crash the OS)
- Aggressively manage/clear the memory cache, so it doesn’t build up and crash mid-generation
- You’ll need to fine tune the generation parameters
- The size of your images (I went for 512x512, which was a good compromise between quality and speed)
- The style in the prompt (cartoon, drawing, painting, …)
- The proper prompting language for each model (it’s not universal, some also allow advance prompting to reduce generation errors)
- You’ll probably want to use whichever pipeline you can over CPU to improve the generation speed.
- Like using MPS (Metal Performance Shaders) for apple silicone
But once it’s setup, the models are downloaded, you should be good to go! But be prepared to be confused and disappointed again, because most likely your laptop and lack of image prompting knowledge, will get you unexpected results. Although psychotic, those images looked overall better than the svg ones. Up close, it was another story…
In order to get the most out of my new image generation script, I decided to try out a bunch of models and see the outcome. And as expected I received a wide range of interesting images, too much to review and decide which to choose from!
So I decided to create a small UI to help le decide which to take. I didn’t let the LLM choose, as I know reckon, it has very poor taste.
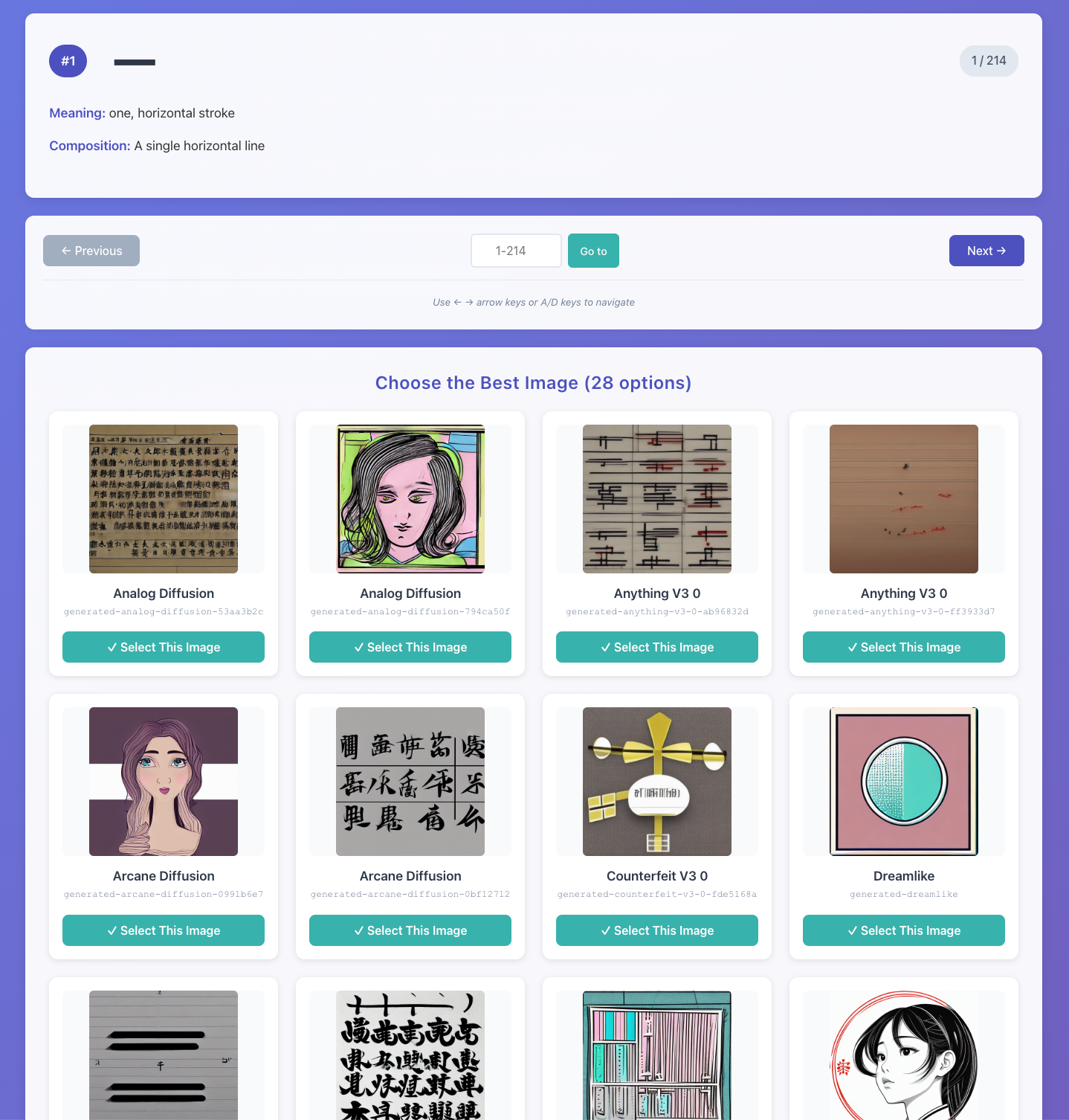
It shows the kanji radical, the meaning and the images. Because, if you don’t have the meaning, it becomes a whole new game of guessing what some of them should represent. As you see above, some of them are quite far from the meaning of the radical.
Simpler prompt did get better usable results, animals usually were easier to represent than abstract concepts. Also I realized that some radical meaning were simply not available in the open source models I was using! (It had a lot of trouble representing an “axe” or a “halberd” for example)
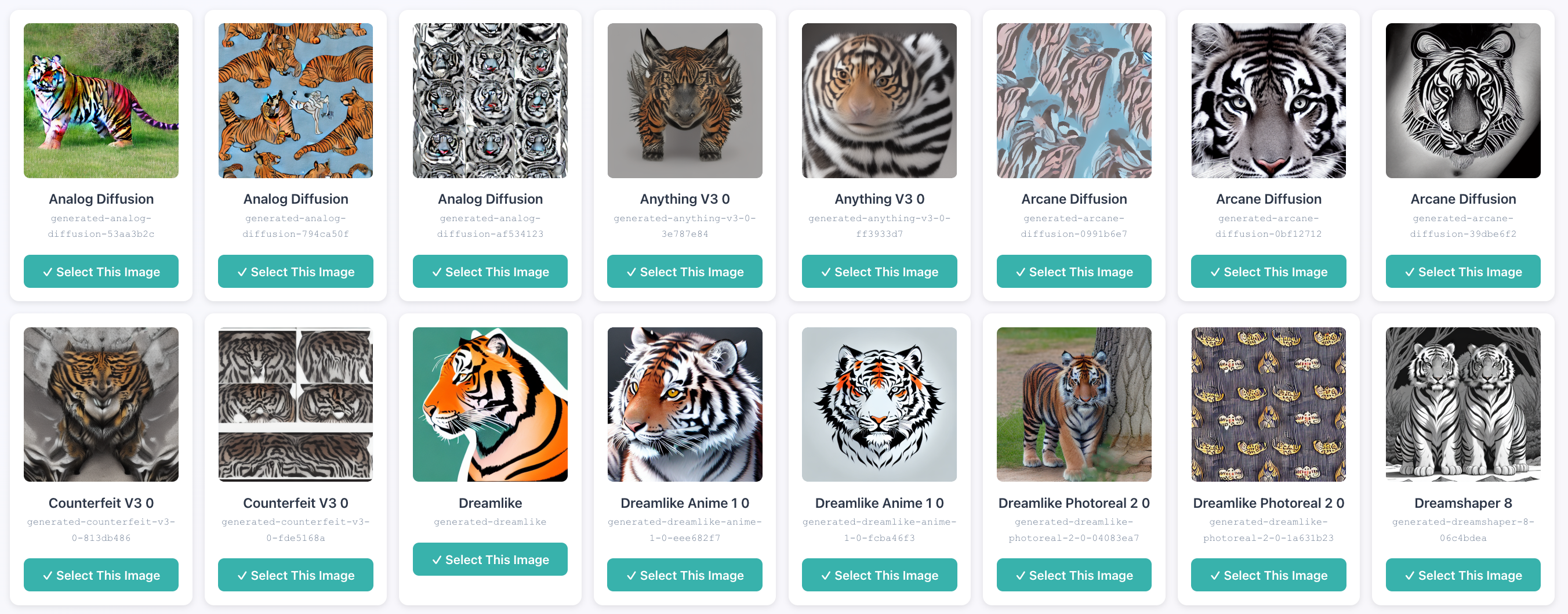
The UI allowed to me to painfully look through over 8000 images (I went wild with models and prompts with sometime 40+ options per radical), and have the selected ones gets copied over in a separate folder to be displayed.
For the remaining ones that did not produce anything usable (almost half of the radicals), I used an alternative option like Gemini to generate them for me. It gave better results, without any complicated prompting. You can’t start to guess how much complexity and model training is hidden behind that.
Conclusion
In the end, the generated image while some were pretty good, were in the end far from my initial goal. At some point in front of the sheer amount of images to review, I started to question my choices and the whole process. I did go through it 😮💨, but realized I could have saved a lot of time by going with a simpler approach.
Looking back at the scripting approach, I created one that only represents the radical in a colored background. While simple, they gave a more consistent both in style and composition representation.



Generating images is fun, and a bit addictive, but it is also time-consuming (generation and review). I really enjoyed playing with the dreamshaper model which gives anime like 3D renders (despite its tendency to put a character in everything).
In the end I’ll probably keep the generated images as I spent too long just to discard it, but the sober script generated ones were probably the better option overall considering time invested vs results.